Everybody knows that the Internet was originally a US military project.
Stephen J. Lukasik, who was Deputy Director and Director of DARPA at the time, explained in Why the Arpanet Was Built:
The goal was to exploit new computer technologies to meet the needs of military command and control against nuclear threats, achieve survivable control of US nuclear forces, and improve military tactical and management decision making.
If you know the history of that period, with the ongoing Cold War, you know that the Internet has been a great geopolitical success, beyond any hope.
The International
Network became more than a medium, it is a message in
itself, a message
of friendship and cultural collaboration between Nations.
A
message against the internationalism of Communism that back then was
fighting for the “abolition of the state”.
All this might seem weird or even incredible to young programmers
born after 1989, but back then, if you were not from USA or USSR,
it was very hard to understand who was your enemy and who was your
friend.
Europe was flooded with powerful propaganda from both sides, and we are still paying the toll of that cultural war today.
The Internet Protocol was so good that it was used to build stacks of higher level protocols: on top of TCP/IP and UDP/IP, we built applicative protocols to fulfill specific needs, such as DNS (a sort of hierarchical phone book), FTP (efficient file transfer), SMTP (mail), and so on.
The Domain Name System
Since IP addresses are numbers used to “call” computers, we created phone books on each computer and tools to lookup such phone books.
It might seem strange to call DNS as a hierarchical phone book, but it becomes a pretty obvious definition once you realize it was born to help with email addressing and delivery.
However, it became soon clear that manual update of such
(completely distributed) phone books was cumbersome, error prone
and inefficient.
Between December 1973 and March 1974 the Internet decided that the Stanford Research Institute Network Information Center
(NIC) would serve as the official source of the
master
hosts file.
Such totally centralized system seems strange these days (with concerns about single point of failures and federated protocols), but SRI served the Internet well for about a decade.
Life was easy back then: to send an UUCP mail to a user named “giacomo” working at a server named “tesio”, you just had to choose the path from your server, with addresses like
aserver!anotherserver!yetanotherserver!tesio!giacomo
where “aserver!anotherserver!yetanotherserver!tesio” was the ordered sequence of servers to connect to deliver the message.
With the growth of the network, between March and October 1982, the modern domain name system was designed and it was soon deployed world wide. The hostnames we use today for email, web browsing, software updates and many other critical tasks were born.
Meanwhile, ARPANET was still under US military control.
The DNS root zone
The Wikipedia page on the DNS root zone dates back to August 1, 2003.
For two
years, it had a wip section titled “The Politics of the DNS root
zone”, but that was removed on June 2005.
The original page author correctly identified it as a very
interesting topic, but it was still waiting to be written. The
matter is actually complex, and hard to tackle without resorting to
primary sources. Thus, it was difficult to handle with
a “Neutral” point of view.
As Wikipedia put it:
The root DNS servers are essential to the function of the Internet […]
The DNS servers are potential points of failure for the entire Internet.
For this reason, multiple root servers are distributed worldwide.
The fun fact is that 10 out of 13 DNS roots are administrated by US based organizations. The root zone itself is distributed by Verisign that directly administers a.root-servers.net and j.root-servers.net. (Ironically, as of today, both websites are served over HTTPS with a broken SSL certificate).
Obviously, to reduce the risk of DDoS attacks, these are not physical servers, but clusters of servers distributed world wide through anycast addressing.
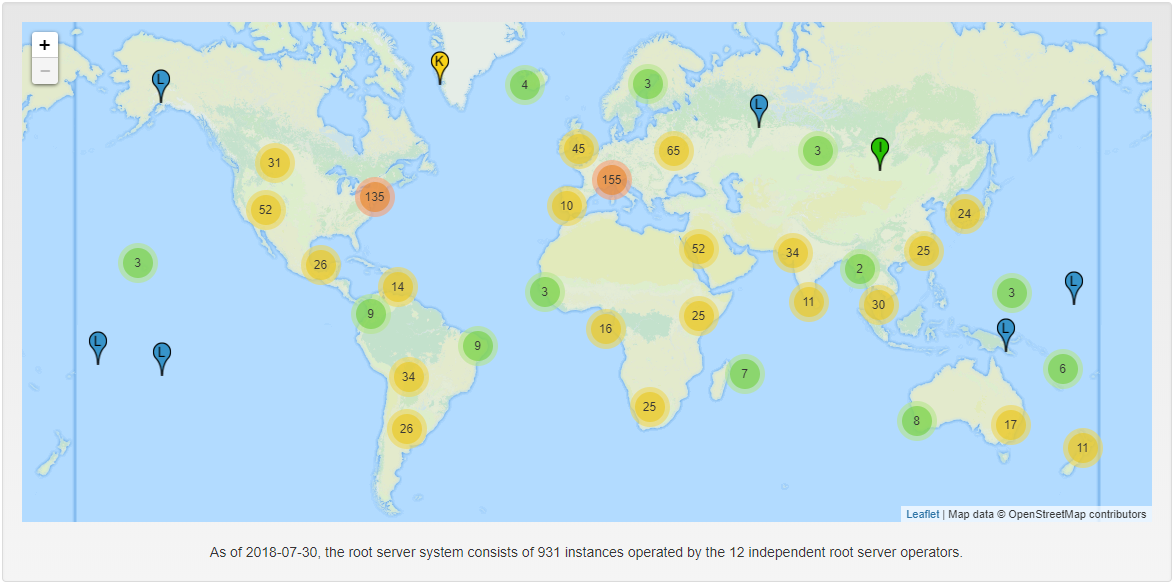
At a glance, we can see that the network should be resilient to attacks.
But if we hack the same page a little to paint a small flag for each server according to the nationality of the organization that administer it, we get a pretty informative projection:
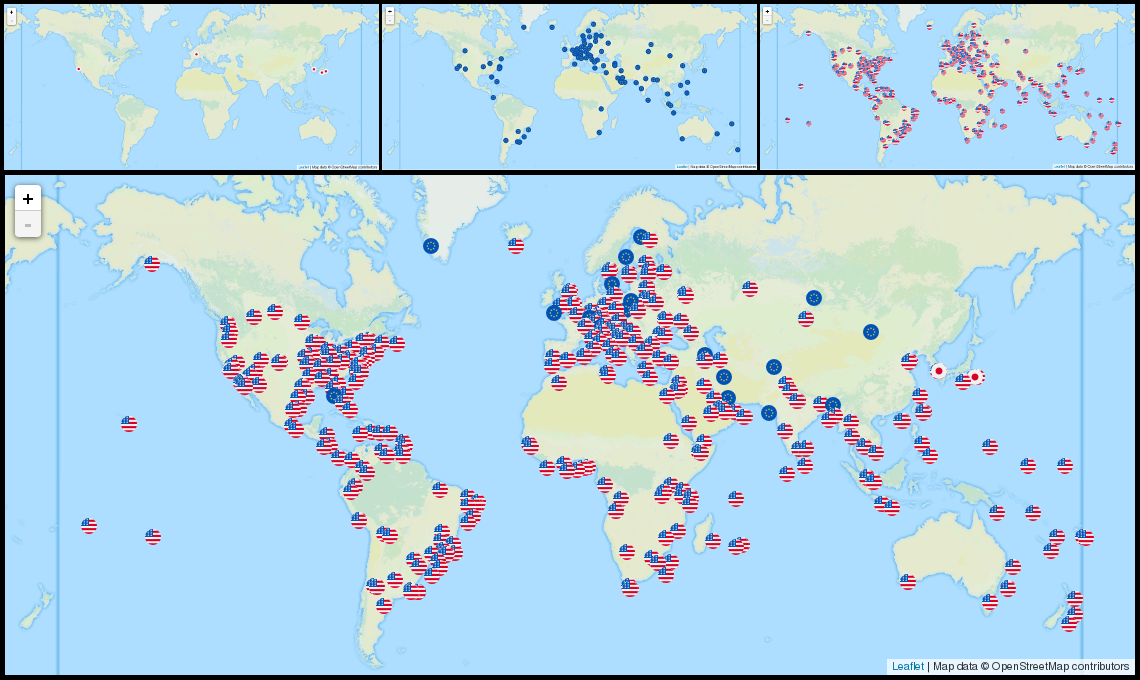
Suddenly, the Great Firewall takes on a completely different meaning.
810 out of 931 DNS
root servers are under US control.
Theoretically, USA could create the cheapest DDoS of history
with perfectly plausible deniability:
just mimic a successful DDoS attack, shutdown your servers in a
region and all other DNS roots will collapse under legitimate
traffic.
Enter the Web.
In March 1989, a young Tim Berners-Lee submitted a proposal for an information management system to his boss, Mike Sendall. ‘Vague, but exciting’, were the words that Sendall wrote on the proposal, allowing Berners-Lee to continue.
Two years later, the first web browser and the first web server were ready.
URI (Universal Resource Identifier), HTML (HyperText Markup Language) and HTTP (HyperText Transfer Protocol) were not the only available solution into that problem space, but somehow they won the race and became widely adopted.
Until the introduction of SSL in 1994 by Netscape Navigator, there was no way to authenticate an HTTP server or to transfer data confidentially, but it was not an issue, since HyperTexts were cultural media, not market places.
However, despite some technical shortcomings, the protocol and the language were simple and the success was so wide that several browser were developed.
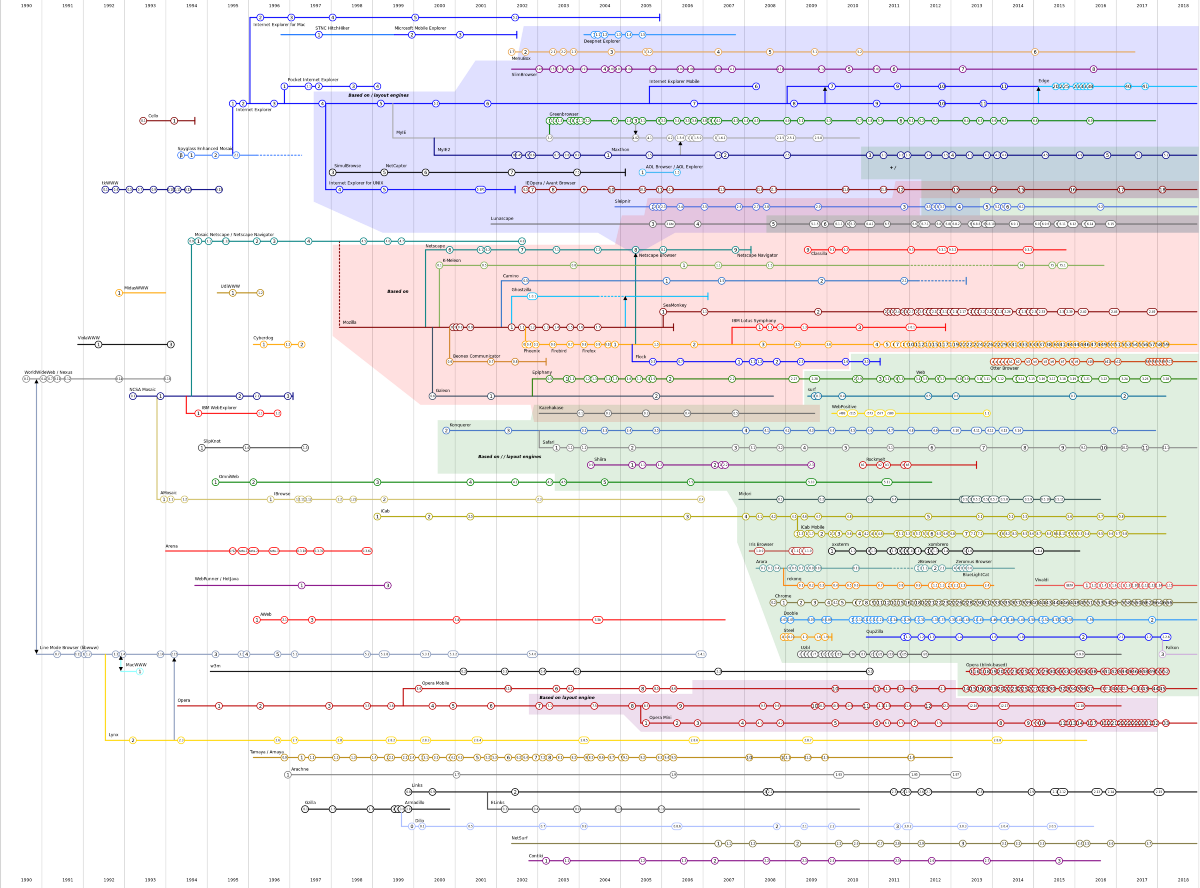
And yet, you are unlikely to know most of them. Why?
The browsers wars
In line with the military origins of the Internet, even the Web began with its own wars: the browsers wars. It was a set of complex commercial competitions — books-worth of material by itself, complete with twists, plots, Trojan horses, cleaver hacks and so on…
However, for our purposes it’s enough to note that in late 2004
one single browser
was winning hands down.
That browser was Internet Explorer 6, serving 92% of the people of the
Web.
I was young back then, and a strong supporter of cool technologies such as XHTML, CSS, XSLT, XSD, Atom and RSS — technologies I used daily in my job as a web developer (or what one would now call a full-stack developer).
The
great idea behind XHTML was to make the web contents easy to parse
from the machines while keeping them easy to write by humans.
With CSS and XSL we were half-way towards a full separation of
concerns between presentation and contents. With XSL-FO I was even
able to extract contents from well designed web pages and produce
nice PDF reports.
The stack had its issues, but overall it was a godsend.
Back then, few lines of XSLT were able to extract contents from web pages, or to remove annoying contents such as Ads.
I was also quite good at JavaScript, a language that was useful when you had to handle the differences between browsers without overloading the server or when you wanted a faster validation feedback on a form.
In this context, IE6 was a pain, but I couldn’t imagine what was going to come.
HTML5
We aimed to provide a “glue language” for the Web designers and part time programmers who were building Web content from components such as images, plugins, and Java applets. We saw Java as the “component language” used by higher-priced programmers, where the glue programmers — the Web page designers — would assemble components and automate their interactions using JavaScript.
The history of JavaScript starts with a 10 days hack from Brendan Eich.
This was in 1995.
JavaScript served its purpose pretty well for almost 10
years.
It was a small little language — a tool to move images on web
pages, to do some early form validation, and few other DOM-related
little stuffs.
It was also common to browse the web without JavaScript
enabled, and every professional web developer used to test
web sites for this use case.
After all, there was a huge effort ongoing to make the Web
accessible.
But suddenly, in 2004, Apple, Mozilla and Opera became “increasingly concerned about the W3C’s direction with XHTML, lack of interest in HTML, and apparent disregard for the needs of real-world web developers”.
I was a
real-world web developer back then (and I still am) but I couldn’t
see the problem. Nevertheless, they created the WHATWG to fix the issue.
After all… they were serving 8% of the Web!
They introduced the concept of Living Standards — ever-evolving documents, unstable by design, that no one can really implement fully.
Somehow, in 2007 they convinced W3C to market the existing version of such unstable drafts as what we now know as HTML5.
HTML5 was not really about HTML. It was just about JavaScript.
Up to
HTML4, the web was an HyperText.
Both the protocol and the markup language were very clear about
that.
Its purpose was to serve interconnected texts to the people.
It was like a public library with great cross-references.
With
HTML5, the web became a platform to deploy and distribute
software.
The useful changes to the markup language were minimal. The only
change worth noticing was the abandon of XHTML. And many asked:
“why?”.
But with HTML5 a whole new set of browser services became available through various JavaScript APIs. These APIs created an huge entry barrier to anyone that wanted to create a browser: most browsers were unable to meet such ever-changing over-complicated requirements, and never implemented the WHATWG’s living standards.
So, HTML5 was a game changer.
The Web stopped to be an HyperText medium serving people.
It
became a marketing
platform serving personal data
collection.
Suddenly, removing annoying contents became harder.
Suddenly, each click, each scroll down, each zoom on a text or a
image became an observable event that can be recorded to profile a
user.
…and JavaScript became a weapon
In 2007, I was really surprised by the W3C abandon of XHTML.
I was annoyed by this, since we had a pretty good infrastructure built upon the XML/XHTML stack. And while I did like JavaScript back then, I didn’t really understand the move.
My boss told me: “You shouldn’t ask why, but who!”. He was right.
In
HTML4, JavaScript was a toy. It had his issues, but it was a
toy.
With the HTML5 usage, a huge number of security issues became
evident.
But with the scandal of Cambridge Analytica I realized that the worst security issue is inherent to JavaScript design itself.
You execute a
custom program controlled by someone else.
Someone else that knows you very well. That can read your
mails.
That knows what you read. That knows what you look for.
That knows where you live. That knows your opinions.
That knows your friends. Your tastes…
Someone else that can serve to you, specifically to you, custom JavaScript that you will run under the laws of your country, without responding to such laws.
A precision weapon
Today, most people cannot really browse the web without JavaScript enabled.
But,
just like Ads target your specific desires, a web site can send you
JavaScript that fills your disk with illegal contents. In the
cache.
The illegal contents will be trivial to find during a forensic
analysis, but the malicious script will be able to remove all
evidences of the breach by simply reloading from its own URI an
harmless version to rewrite the cache.
This is just one of the possible attacks, but not to every visitor; it would be too easy to catch: it’s just for you, because you are an annoying guy that does not conform with the masses.
Unlike the DNS system (a coarse weapon, only for the USA’s use, and only capable of targeting large regions), JavaScript is a weapon to target specific persons with plausible deniability.
The servers know
you. Very well. Very very well. ;-)
And they serve you JavaScript programs that you execute
blindly.
What can go wrong?
Enter, WebAssembly!
JavaScript is a poor language.
Dumb
developers obfuscate it and smart hackers deobfuscate it.
And even in obfuscated form, a motivated JavaScript programmer can
read and debug it anyway. Worse, as a reminiscence of old times,
when the Web was a library instead of a market place, all browsers
have that annoying View Source button that
let you inspect the actual code executed by the browser, not just
what such code want you to see.
Even as
a weapon… JavaScript is a pain in the ass!
If you serve malicious JavaScript to a single user the probability
that you will get caught is low, but it increases by an incredible
margin when serving hackers and web developers.
We really need a binary format that no human could read!
And we really need to remove that annoying “View Source” button!

Houston, we have a problem here...
Seriously, WebAssembly is the worst idea
since JavaScript in browsers.
Not only because it’s a binary blob served by foreign
companies but run on your PC, under the law of your
country, but because they know you, your
relations, your interests, and will “customize” that blob.
Even if implemented perfectly, without a single security issue, it’s a weapon.
You might object that JavaScript is already a weapon ready to fire on every PC and every smartphone out there. A weapon that constitutes a threat to free speech even if we ignore the power of Google and friends.
And you
would be right.
JavaScript is a
dangerous weapon that should be disarmed.
I cannot really understand how European states let this happen.
I’d like to think they were bribed, but the sad truth is that they do not understand the matter. Not even a little bit.
But
developers do!
It’s time for
developers to fix this mess.
Let’s start from the
client side.
Mozilla, I’m looking at you.
As for the JavaScript issue, here and here a couple of trivial PoC exploits.
It worth noticing, a
few months after the vulnerability report, that neither Mozilla nor Chromium are informing their users.
This shows that the real vulnerability is not JavaScript, but
trusting them.
Many thanks to @enkiv2 that kindly copy-edited this article to fix my bad English… and to the 1536 braves who read through that mess anyway.